Le métier de statisticien
CHAPITRE IV
La technique statistique
Retour à la table des matières
La distinction que nous proposons entre technique et méthode ne
doit pas masquer les relations qui existent entre ces deux phases. D'abord, la frontière
est assez floue : la mise au point d'un questionnaire est-elle une opération technique ou
méthodologique ? Nous avons répondu : technique. Mais cela peut se discuter.
Par ailleurs, l'exercice des responsabilités techniques forme
en profondeur le statisticien. Les qualifications et les niveaux très divers des
personnes qui concourent à la production d'information font des services statistiques un
univers social composite ; même s'il n'est pas exactement représentatif, il est assez
varié pour donner à celui qui y travaille, à condition qu'il ne s'enferme pas dans son
propre milieu, une ouverture sur les problèmes de notre société. Ensuite, et toutes
proportions gardées, les exigences de qualité et de délais, la gestion d'un grand
volume de travaux, les problèmes d'organisation, posent au statisticien des questions
analogues à celles qui se posent à un industriel, un commerçant ou un gestionnaire. Au
total, la participation aux opérations techniques est le gage d'un enracinement dans le
concret, d'une appréhension peut-être terre à terre mais intuitive, rapide et correcte
des besoins et des problèmes des utilisateurs de l'information. Le statisticien actif
n'est pas un bureaucrate coupé du réel.
Enfin, c'est bien souvent au cours des opérations techniques
qu'apparaissent des défauts de conception. Une nomenclature mal adaptée entraîne des
réponses confuses, une définition ambiguë est comprise de différentes façons,
certaines questions ne peuvent pas recevoir de réponse. Le contact avec le " terrain
", que seules les opérations techniques procurent, occasionne donc des
améliorations méthodologiques et permet d'accumuler une expérience grâce à laquelle
la conception des opérations futures pourra être améliorée.
On voit à quel point technique et méthode sont mêlées l'une
à l'autre. Et pourtant, il fallait les distinguer ; car elles relèvent malgré tout
d'attitudes différentes, elles constituent des " moments " différents du
travail. La méthode est placée sous le signe du choix ; elle ne se conçoit pas sans une
certaine liberté d'esprit, indispensable pour s'adapter aux caractéristiques des divers
domaines étudiés. La technique, par contre, est placée sous le signe de la rigueur, du
répétitif et du normalisé. La méthode trace la voie, et la technique est sur les
rails. Une fois définies les options, la recherche de résultats comparables entre
eux et dans le temps oblige à une sorte de fixité des concepts, à des vérifications
précises, voire tatillonnes. Ainsi le travail statistique associe deux attitudes qui
semblent presque incompatibles, tant elles nécessitent des dispositions d'esprit
différentes ; mais c'est justement cette association qui garantit la qualité d'ensemble
de la démarche. Et d'ailleurs, même s'il présente quelques difficultés, le va-et-vient
entre les deux attitudes n'est pas désagréable, car l'une délasse de l'autre : c'est
parfois un vrai plaisir, quand on a longuement réfléchi et discuté, et que l'on a eu le
sentiment de rêver quelque peu, de se remettre " au charbon (1) " et de
reprendre la matière à pleins bras. Et vice versa.
Il est significatif que les livres sur la statistique réservent
souvent plus de place aux techniques qu'aux méthodes. Le terrain technique est plus
rassurant et aussi, il faut le dire, beaucoup mieux connu et mieux balisé par les
statisticiens. Il se prête davantage à la formalisation, aux préceptes, aux recettes,
à l'enseignement. Enfin, une conception de la statistique qui se limite à la technique
élude quelques questions philosophiques difficiles, qu'elle contourne à l'aide de
considérations volontiers moralisantes sur l'objectivité, le sérieux, etc.
Et il est vrai que, dans le cadre défini par les choix
méthodologiques, la notion d'objectivité reprend toute sa valeur. Il serait, en
effet, contraire à la nature même du travail statistique de modifier une mesure parce
qu'elle est surprenante ou déplaisante ; il serait tout aussi aberrant de choisir les
méthodes de sorte que les résultats obtenus ne puissent être que rassurants et
agréables (à moins que l'objectif que l'on se donne ne soit l'euphorie ; mais alors il
faut en être conscient). La conception des méthodes est une opération de longue
haleine, qui nécessite une réflexion sur les relations entre méthodes et objectifs.
L'objectivité technique, elle, est de tous les jours.
La technique comporte un grand nombre d'opération détaillées,
toutes importantes parce que l'échec d'une seule des phases du travail technique
compromet la qualité du résultat. Pour éviter les longueurs d'un exposé didactique
complet (2) - qui n'entrerait d'ailleurs pas dans notre propos -, nous poursuivrons selon
le procédé utilisé au chapitre précédent : on prend une opération fictive, et on la
suit dans ses différentes phases, tout en signalant au fur et à mesure les variantes qui
peuvent être utilisées (3).
Les éléments de base : répertoires et questionnaires
Qui interroger, quelles questions poser : voilà le point de
départ de la collecte. Le répertoire (4) contient la liste des unités à
interroger ; le questionnaire contient les questions à poser.
Lors de la phase méthodologique, on a défini la nature des
unités à interroger. Il s'agit de passer de cette définition de principe à une liste
comportant des noms et des adresses, que l'on pourra utiliser pour lancer l'enquête. De
plus, cette liste devra être codée, triée et classée selon certaines des nomenclatures
choisies (on classera des établissements, par exemple, par classe de taille, activité et
région ; des ménages selon la catégorie sociale du chef de ménage, la taille de la
commune de résidence, etc.), afin de faciliter l'organisation de l'enquête.
Au total, le répertoire résulte d'une interaction entre les
nomenclatures et la définition des unités. Il faut, pour le constituer, disposer d'une
liste de base dont on triera les éléments : S.I.R.E.N.E. (5) pour les enquêtes auprès
des entreprises, le recensement de la population pour les enquêtes auprès des ménages,
le recensement de l'agriculture pour les enquêtes agricoles, etc. Cette liste de base
peut être à l'occasion complétée par des mises à jour partielles, par exemple
lorsqu'elle a trop vieilli et que la " population " s'est modifiée.
L'importance du répertoire est fondamentale. En effet, une
enquête exécutée à partir d'une liste fausse donnera par la suite des résultats
erronés, quel que soit le soin apporté à son exécution. Les unités présentes à tort
pourront être sans doute éliminées après la collecte (elles risquent cependant de
fausser les opérations de sondage), mais les unités absentes ne pourront pas être
retrouvées : un répertoire faux entraîne donc des erreurs par défaut, souvent
importantes. Certaines enquêtes sur la production industrielle, réalisées par des
syndicats patronaux, comportent pour cette raison des sous-estimations de 30 % à 50 %.
Il est très difficile de réaliser un répertoire parfait. Des
entreprises sont créées, changent d'activité, fusionnent, se scindent, cessent
d'exister ; les personnes naissent, déménagent, meurent ; les exploitations agricoles se
regroupent, se divisent, disparaissent : le mouvement même des choses mine constamment la
qualité des répertoires qui doivent être rectifiés par des mises à jour continues,
onéreuses et fastidieuses. Ces mises à jour prennent du temps, et le répertoire est
toujours en retard par rapport à la réalité. On peut tout au plus évaluer ce
décalage, et faire en sorte qu'il n'ait pas de trop graves conséquences.
C'est au moment de la constitution du répertoire que l'on
réalise les sondages : on divise la population en classes jugées homogènes, et
on tire dans chaque classe le nombre d'unités nécessaire pour obtenir, au moindre coût,
un résultat significatif. Nous ne nous étendrons pas ici sur les sondages : leur
technique, qui répond à des principes très simples, est parfois dans les applications
d'une réelle complexité parce qu'elle peut s'adapter très souplement aux
particularités de l'objet étudié (6). La qualité des enquêtes d'opinion (et en
particulier des enquêtes sur les intentions de vote, si discutées) dépend surtout de la
bonne rédaction des questionnaires et de la qualification des enquêteurs.
Passons au questionnaire. Il doit respecter une contrainte de
bon sens : on n'obtiendra une réponse que si la personne enquêtée est capable de la
fournir sans que cela lui demande un trop gros travail. Par ailleurs, les nomenclatures
(de postes comptables, de produits, etc.) définissent les rubriques possibles, dans
lesquelles on choisira donc en fonction des caractéristiques de l'unité. Les techniques
de rédaction d'un questionnaire ont fait l'objet de longues études (7) : nous n'y
reviendrons pas. Mentionnons les dives types de questions (" ouverte " ou "
fermée ", " qualitative " ou " quantitative "), les divers types
de codages, etc. La rédaction d'un questionnaire demande que l'on ait le temps de la
réflexion et doit se faire de préférence à plusieurs : on n'obtient pas du premier
coup un texte sans ambiguïté, cohérent et réaliste.
La collecte
Elle se fait en pratique soit par voie postale, soit en employant des
enquêteurs.
Avec la collecte par voie postale, nous atteignons le point le
plus terre à terre de la technique. L'objectif est d'obtenir un taux de réponse élevé
(supérieur à 95 % dans l'industrie) dans un délai assez bref pour que les résultats
finals présentent encore un intérêt lorsqu'on les publiera. Cela demande une gestion
très serrée des envois, une bonne coordination avec le bureau de poste dont on dépend ;
cela demande aussi que l'on organise de nombreux rappels : dans une enquête industrielle
obligatoire, une entreprise qui s'obstine à ne pas répondre recevra cinq correspondances
(l'envoi, deux rappels, une mise en demeure, un constat de non-réponse). Si la moitié
des entreprises répondent à chaque correspondance, il ne restera à la fin que 3 % de
non-réponses environ.
La collecte par enquêteurs relève d'une autre organisation.
Elle est beaucoup plus coûteuse, mais beaucoup plus féconde. On peut poser des questions
plus compliquées, que l'enquêteur expliquera ; la réponse sera obtenue sous une forme
plus correcte, car c'est l'enquêteur qui la rédige ; on peut poser aussi des questions
" ouvertes ". La relation de l'enquêteur à l'enquêté, la formulation des
questions répondent à tout un " cérémonial " destiné à établir un "
contact " favorable... Sur ce point aussi, la littérature abonde.
L'expérience et le sérieux des enquêteurs sont déterminants.
L'organisation d'un réseau d'enquêteurs compétents ne s'improvise pas. Les organismes
qui recrutent des enquêteurs pour des opérations occasionnelles ont des déboires avec
ceux qui " bidonnent " - c'est-à-dire qui remplissent les questionnaires en
chambre, sans se déplacer. Ces questionnaires peuvent être assez aisément décelés à
la vérification, mais il faut alors recommencer le travail.
La vérification
Les réponses reçues doivent être vérifiées, car elles sont
souvent incorrectes. Il est bien rare qu'un questionnaire soit utilisable tel quel, sans
quelque rectification.
Souvent, le questionnaire comportera des lacunes : la personne
enquêtée n'a pas pu répondre à certaines questions. Cela résulte la plupart du temps
d'un scrupule excessif, spécialement dans les enquêtes auprès des entreprises :
habituées à la précision comptable, les personnes qui remplissent le questionnaire ne
peuvent se résoudre à indiquer un résultat approximatif. Or les exigences de la
statistique en matière de précision sont beaucoup moins strictes que celles de la
comptabilité, et ne vont ni jusqu'au centime ni même jusqu'au franc. Tel chef
d'entreprise, qui remplit un questionnaire " sous la jambe " (de son point de
vue) en fournissant des résultats exacts mais imprécis s'imagine saboter la statistique
alors qu'il n'en est rien. Par contre, l'homme à l'esprit méticuleux et étroit qui
donne des résultats très précis mais ne songe pas à vérifier les ordres de grandeurs
essentiels est pour la statistique le pire des fournisseurs. Relevons en passant la
distinction entre exactitude et précision. " La bataille de Waterloo a eu lieu le 18
juin 1815 " : précis et exact. " Elle a eu lieu au XIXe siècle " : exact
et imprécis. " Elle a eu lieu le 21 mai 1830 " : précis et inexact.
L'exactitude est une caractéristique logique de l'information (une information ne
peut pas être à la fois exacte et inexacte), alors que la précision est une
caractéristique pratique (selon les usages qui en sont faits, une information sera
précise ou imprécise, les uns travaillant au mètre près et les autres au micron
près).
Une première vérification " manuelle " servira à
repérer les erreurs les plus grossières. Elle se fait en même temps que le "
codage ", transcription numérique des indications qualitatives. Puis le
questionnaire est " saisi " - c'est-à-dire que l'information qu'il contient est
transcrite sur un support permettant les traitements automatiques (cartes perforées,
bandes ou disques magnétiques). Il est ensuite soumis à des opérations de vérification
automatique.
Les méthodes de vérification automatique sont en pleine
évolution, et de grands progrès sont possibles en ce domaine ; elles sont en pratique
assez compliquées. Le principe est en tout cas simple : il s'agit d'utiliser la puissance
et la rapidité des calculateurs automatiques pour repérer les erreurs qui peuvent
subsister après la première vérification manuelle, ou qui peuvent s'être produites
lors de la saisie.
On distingue, selon un vocabulaire un peu prétentieux,
vérification syntaxique et vérification sémantique ; la première sert à s'assurer que
l'enregistrement (transcription du questionnaire après saisie) a bien la forme qu'il doit
nécessairement avoir : toutes les cases sont bien remplies, les codes ont des valeurs
acceptables (8), les additions sont exactes, etc. La vérification sémantique est plus
difficile : elle vise à contrôler la vraisemblance des informations, en confrontant les
réponses entre elles, et en calculant dives ratios dont l'expérience a montré qu'ils ne
sortaient guère de certaines " fourchettes ". La vérification syntaxique
décèle des erreurs ; la vérification sémantique décèle des anomalies, qui
correspondent soit à des réponses fausses, soit à des valeurs exceptionnelles des
ratios : une unité très originale peut fort bien posséder des ratios extraordinaires.
Le gestionnaire d'enquête reçoit donc des " messages
d'erreur " et des " messages d'anomalie ". Le message d'erreur doit
impérativement donner lieu à une correction ; l'anomalie peut être, après recherche
d'informations supplémentaires, soit corrigée (si elle provient d'une réponse fausse)
soit confirmée (s'il s'agit d'une originalité).
Mettre au point une batterie très complète de messages
d'erreur est affaire de soin et de temps. Mais la mise au point des messages d'anomalie
est plus délicate. Imaginons, en effet, que dans le dessin de la page 52 la zone
entourée d'un trait plein représente l'ensemble des réponses fausses, et que les zones
entourées de traits pointillés désignent les cas signalés par des messages d'anomalie
choisis de diverses façons.
Dans le cas A, toutes les réponses fausses sont signalées ;
mais le message signale aussi beaucoup d'anomalies qui ne correspondent pas à des
réponses fausses, et que le gestionnaire devra donc confirmer. A l'usage, le gestionnaire
perd confiance dans ce message : sachant que bien souvent la vérification aboutit à une
confirmation, il aura tendance à ne pas prendre ce " signal d'alarme " au
sérieux et donc à toujours confirmer cette anomalie sans vérification.
Dans le cas B, les anomalies signalées correspondent toutes à
des réponses fausses : ce message sera donc à l'usage pris très au sérieux par les
gestionnaires. Mais beaucoup de réponses fausses subsisteront dans les enregistrements,
que le message n'aura pas signalées.
Dans le cas C, les messages sont indépendants des réponses
fausses : le résultat est pratiquement le même que dans A.
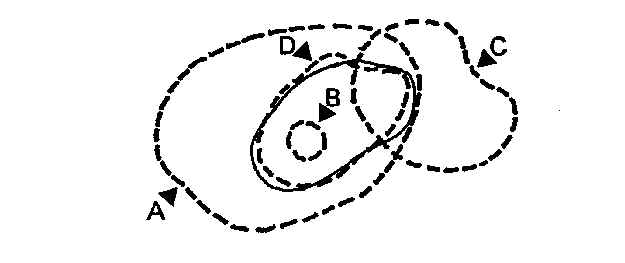
L'idéal est d'avoir un message du type D, dont le domaine soit
aussi proche que possible de celui des réponses fausses. La recherche de messages
d'anomalie de ce type demande un travail complexe, de nombreux essais sur les ratios, sur
les intervalles d'acceptation et de rejet et sur les combinaisons de ratios.
Les informations nécessaires pour corriger les erreurs ou
confirmer les anomalies sont collectées par le moyen d'enquêtes complémentaires, de
correspondances écrites ou téléphoniques. L'enregistrement dûment modifié est soumis
de nouveau au programme de vérification (car il arrive souvent qu'une correction
entraîne l'édition de nouveaux messages d'erreur ou d'anomalie) et on recommence
jusqu'à ce que le programme de vérification ne trouve plus rien à redire aux
enregistrements. On a alors obtenu ce que l'on appelle un fichier propre enregistré sur
bande ou disque magnétique, à partir duquel on pourra procéder aux exploitations
informatiques.
Si l'on disposait de messages d'anomalie qui signalent à coup
sûr toutes les réponses fausses, le " fichier propre " serait en même temps
un fichier exact, puisque toutes les erreurs auraient été corrigées. Mais il y a
toujours un écart entre les anomalies signalées et les réponses fausses ; et cet écart
induit lui-même des erreurs dans la conduite des statisticiens. En effet, les opérations
de vérification sont souvent faites dans une atmosphère un peu survoltée, car il faut
atteindre un rendement élevé pour pouvoir publier dans des délais convenables ; le
programme automatique, lorsqu'il rejette plusieurs fois de suite un enregistrement que
l'on pensait avoir pourtant bien corrigé, apparaît alors comme un adversaire têtu et
mesquin. Il est tentant de le faire taire en confirmant les anomalies, même si l'on n'est
pas bien certain qu'elles ne recouvrent pas des erreurs. Mais il est plus tentant encore
de " raboter " l'anomalie, de la corriger de force, de faire entrer le cas
particulier dans la norme en donnant un coup de pouce aux variables concernées. Trop
souvent, le statisticien aura tendance à considérer l'anomalie comme une erreur ; il
n'osera pas utiliser la procédure de confirmation, qui engage de façon visible son
jugement et sa responsabilité, et supprimera les originalités individuelles dont le
repérage est pourtant un des apports les plus intéressants d'une opération statistique.
Par ailleurs, certaines informations se prêtent mal à la
vérification automatique, et ne peuvent être contrôlées que moyennant un travail
" manuel " délicat : c'est le cas, par exemple, lorsqu'il s'agit de vérifier
si une nomenclature a été bien comprise par la personne interrogée. Cela demande que
l'on sache réfléchir sur le sens des mots, chose qu'un ordinateur ne sait pas faire et
qui ne peut donc pas donner heu à des messages d'anomalie. Les statisticiens qui veulent
produire rapidement un " fichier propre " risquent de négliger cette
vérification, et de concentrer leurs efforts sur des erreurs moins importantes mais plus
visibles.
Il y a là des écueils que l'on ne peut éviter que par un
effort de réflexion et de critique qui permette aux statisticiens de conserver, même au
milieu des soucis de la gestion, une claire conscience des finalités de leur travail,
d'apprécier l'importance relative des diverses vérifications et de ne pas être
excessivement intimidés par les messages d'anomalie.
Les formes d'organisation du travail taylorisées,
hiérarchisées, lorsqu'elles enferment les exécutants dans des tâches parcellaires dont
ils ne peuvent pas percevoir le sens, conduisent presque inévitablement à une pratique
maladroite des vérifications ; il en résulte, pour la qualité des résultats, de
sérieux dommages qui ne sauraient être compensés par les gains de rendement, mesurés
par exemple par le nombre de questionnaires traités chaque jour par un agent.
L'extrapolation
Malgré l'insistance que l'on a mise à obtenir des réponses,
certaines unités n'ont pas répondu. Si l'enquête est faite par sondage, il peut suffire
pour corriger ce défaut de modifier a posteriori les taux de sondage dans les calculs
(encore que cela présente des risques : un tel mode de correction suppose que les unités
non répondantes aient des caractéristiques analogues à celles des répondantes, ce qui
peut être faux). Mais si l'enquête est exhaustive, comme le sont la plupart des
enquêtes portant sur les entreprises au-delà d'une certaine taille, il faut, par un
procédé ou un autre, estimer les réponses manquantes : c'est l'extrapolation.
Supposons que l'on néglige d'extrapoler les non-réponses dans
une enquête industrielle mensuelle. Telle grande entreprise omettra de répondre un mois
donné, mais répondra le mois suivant ; cela se produit souvent, car durant certaines
périodes (lorsqu'il faut faire les comptes, au moment des vacances, etc.) les entreprises
répondent moins bien. Si l'on n'extrapole pas, l'évolution des statistiques sera très
influencée par les fluctuations du taux de réponse ; elle perdra une bonne part de sa
signification économique. C'est là une évidence aveuglante, mais l'expérience montre
qu'elle est souvent ignorée. Nous nous rappelons encore la vertueuse indignation d'un
" statisticien " à qui nous avions conseillé d'extrapoler : " Pour moi la
statistique est une chose sérieuse, nous dit-il ; je ne publie que des résultats dont je
suis sûr et qui correspondent à des questionnaires que j'ai effectivement reçus et
totalisés. Je me refuse à deviner les résultats de ceux qui ne m'ont pas répondu.
"
Que ce soit sottise ou négligence, l'absence d'extrapolation ou
l'extrapolation erronée est un défaut fréquent des enquêtes ; quand elle s'associe -
comme c'est le cas en général - avec la mauvaise tenue du répertoire, on obtient des
résultats qui n'ont rien à voir avec la réalité, que ce soit en niveau ou en
évolution.
Mais comment " estimer " les réponses manquantes ? Il
convient qu'elles ne soient pas trop nombreuses (pas plus de 5 % du total dans une
enquête industrielle, d'après une pratique tout à fait empirique). Ensuite, il ne faut
pas qu'elles correspondent à de trop grosses unités : on est parfois obligé de retarder
une publication parce que l'on attend le résultat d'une très grande entreprise.
Pour une entreprise d'importance moyenne, on cherchera à se
procurer par téléphone quelques informations essentielles, puis on établira
l'évaluation de sa réponse en partant de ces éléments et en calculant les autres à
partir de ratios moyens et des réponses de l'entreprise aux enquêtes précédentes. Pour
remplacer une petite entreprise, on choisira au hasard une autre entreprise pas trop
originale dans les mêmes " strates " de taille, d'activité et de lieu, et on
la " dupliquera ", c'est-à-dire qu'on la comptera deux fois dans les calculs ;
ou bien on se contentera de redresser les résultats à proportion des effectifs ou du
chiffre d'affaires. Tout cela ne relève que du soin, du bon sens, et il n'en est que plus
étonnant que cela soit aussi souvent mal fait.
On peut espérer que le progrès des techniques statistiques
permettra d'améliorer les méthodes d'extrapolation, et de dépasser le stade de
l'artisanat tâtonnant où nous nous trouvons encore. Peut-être sera-t-il alors possible
d'obtenir des résultats significatifs avec un taux de réponse faible, et de procéder à
des publications rapides comportant des indications sur la précision. Mais tout cela est
encore expérimental.
L'exploitation et la fusion des fichiers
Une fois établi le " fichier propre ", reste à
procéder à son exploitation. Les programmes usuels permettent d'établir automatiquement
tous les tableaux imaginables, en croisant les diverses nomenclatures entre elles. Nous
verrons dans le chapitre suivant comment cette masse d'informations doit être analysée
pour préparer les publications. Nous reviendrons dans la troisième partie sur ce
qu'apportent les tableaux croisés.
Un fichier d'enquête se prête aussi à d'autres usages que
l'exploitation directe : on peut l'utiliser pour vérifier un autre fichier (par exemple,
pour établir des messages d'anomalie, on compare les réponses d'une même unité à deux
enquêtes successives) ; on peut aussi le fusionner avec un autre ficher.
Les opérations de fusion, encore relativement rares,
multiplient les possibilités de la production statistique. La fusion de fichiers est
simple dans son principe. Supposons que nous disposions de deux enquêtes différentes
réalisées sur une même population, et que chaque unité soit repérée par un même
identifiant dans les deux fichiers. Il suffit de repérer les deux enregistrements
correspondant à chaque unité. Puis on réunit ces deux enregistrements en un seul et
l'ensemble de ces nouveaux enregistrements constitue un nouveau fichier dit "
fusionné ". La fusion augmente fortement les possibilités d'exploitation : nous
allons le montrer sur un exemple fictif très simple. Supposons que l'on fasse une
enquête sur les ménages pour observer la catégorie socioprofessionnelle (C.S.P.) du
chef de ménage selon une nomenclature en dix postes ; l'exploitation de cette enquête
permettra de construire un petit tableau de dix cases, donnant le nombre de ménages par
C.S.P. Supposons que l'on fasse une autre enquête pour observer le revenu du ménage, et
qu'on le code selon une nomenclature en vingt tranches de revenu : là aussi, on aura un
tableau de vingt cases. Si on fusionne les deux fichiers, on pourra classer chaque ménage
simultanément selon les C.S.P. et la tranche de revenus, et donc produire un tableau
croisé de 10 x 20 = 200 cases. On peut donc dire, d'une façon tout à fait exacte, que
la fusion de fichiers multiplie les possibilités de l'exploitation.
Dans la pratique, la fusion de deux fichiers est une opération
très difficile : les identifiants des unités peuvent être erronés, ce qui complique la
recherche des couples d'enregistrements. Par ailleurs, les champs couverts par les deux
fichiers peuvent ne pas coïncider. Les spécialistes de la fusion de fichiers ont
développé toute une technique et utilisent un vocabulaire qui leur est propre : les
fichiers sont d'abord " mis en forme ", car les enregistrements ne sont pas
forcément construits de façon à rendre la fusion aisée ; plusieurs passages d'"
interclassement " sont nécessaires pour rechercher les couples et " apparier
" un nombre suffisant d'unités. Après " réintroduction " des unités
absentes dans l'un ou l'autre fichier, des " confrontations " portant sur les
variables communes aux deux enquêtes permettent de déceler des incohérences ou des
erreurs que l'on corrige par des " mises à niveau ". Toutes ces opérations
doivent être faites par un personnel expérimenté ; elles nécessitent une consommation
étonnante de documents informatiques, de bordereaux, etc. ; elles sont d'un coût élevé
et comportent des délais assez longs, de sorte que l'exploitation améliorée et enrichie
que l'on peut faire après une fusion de fichiers n'est disponible que longtemps après la
première exploitation.
L'utilisation de sources d'information d'origine administrative
Dans la description que nous venons de donner, le statisticien
construit lui-même entièrement son instrument, en partant des indications fournies par
son client : il choisit le champ de l'étude, son découpage, les nomenclatures, etc. Mais
il peut accéder directement à des sources d'information énormes, les fichiers
administratifs, qu'il exploitera ou fusionnera avec d'autres sources ; cet accès est bien
sûr conditionné par l'accord de l'administration " propriétaire " du fichier,
accord généralement lié au respect du secret professionnel sur l'information
individuelle. C'est ainsi que les statisticiens peuvent exploiter de nombreuses
informations administratives ou les fusionner avec d'autres fichiers : déclarations
fiscales des particuliers et des entreprises, déclarations concernant l'emploi et les
salaires, etc.
A priori, la masse d'information contenue dans ces fichiers
éblouit, et c'est le mot de " trésor " qui vient à l'esprit lorsqu'on reçoit
par exemple le fichier des déclarations fiscales des entreprises (une vingtaine de bandes
magnétique). On découvre cependant à l'usage que les sources administratives sont
difficiles à exploiter. En effet, l'objectif que vise une administration lorsqu'elle
constitue un fichier n'est pas principalement statistique : le fichier est avant tout une
aide à la gestion (par exemple, il permet d'expédier automatiquement des avis de
recouvrement). Les variables importantes pour la gestion sont vérifiées avec soin, mais
d'autres peuvent être erronées ; il en est de même des codages, et en particulier du
numéro d'identification. Le fichier sera bien souvent lacunaire (par exemple, il ne
comportera pas les réponses reçues en retard, et qui sont traitées dans un autre
circuit). De plus, les définitions et nomenclatures utilisées par une administration
coïncident rarement avec ce que le statisticien souhaiterait. En outre la nature même de
l'opération administrative à laquelle est liée l'information peut provoquer de fausses
déclarations. Au total, un fichier administratif n'est pratiquement jamais un "
fichier propre ", et il est construit selon des découpages conceptuels souvent
inadaptés à la statistique. De longs travaux de correction et de redressement sont
nécessaires pour pouvoir exploiter ces fichiers, et des pans entiers de l'information se
révèlent inutilisables. La déception est souvent à la mesure des espoirs qu'avait fait
naître l'accès au " trésor ".
Cela n'a rien de surprenant : nous avons vu comment une
opération statistique devait, lors de sa phase méthodologique, être définie en
relation avec une action et aux besoins d'information liés à cette action. L'information
rassemblée à l'occasion d'opérations administratives peut être très bien adaptée à
ces opérations sans être pour autant directement utilisable par les statisticiens, à
moins qu'ils n'aient été consultés lors de la conception des documents de collecte, ce
qui est exceptionnel.
La situation est différente si, comme cela se produit de plus
en plus, la gestion administrative elle-même s'organise autour du fichier informatique,
et si de surcroît la conception des documents de base et de la structure du fichier se
fait en tenant compte des impératifs de la statistique. Si une telle évolution se
confirme, on peut espérer que les sources administratives deviendront de plus en plus
utilisables par le statisticien, ce qui peut permettre d'importantes économies de
collecte, et aussi ouvrir l'accès à des informations que l'on n'aurait jamais envisagé
d'obtenir par voie d'enquête en raison du coût de l'opération (9).
Revenons-en à la représentation de l'information qui se trouve
derrière l'image du " trésor " que nous avons évoquée à l'instant :
l'information est assimilée à de la monnaie, ou tout au moins à un produit éminemment
échangeable, et la tâche du statisticien serait alors de la capter, de la canaliser et
de la redistribuer (de même que la tâche du financier est de capter, canaliser et
redistribuer l'épargne). Mais l'image monétaire est trompeuse ; si l'on éprouve
vraiment le besoin d'une analogie, il vaudrait mieux comparer l'information à la
marchandise, répartie selon des catégories dont chacune correspond à une technique de
production et un besoin déterminés : analogie inexacte à certains égards, car
l'échange, la circulation et la transmission de l'information ne ressemblent guère à
ceux des marchandises ; elle permet toutefois de considérer un " stock "
d'informations d'origine administrative non comme un trésor, mais comme un entrepôt
rempli de biens dont une partie est avariée ou inutile, et qu'il faut trier avant usage.
Nous retrouverons l'image monétaire de l'information - et ses inconvénients - lorsque
nous parlerons dans le chapitre suivant des " banques de données ".
Le contrôle des enquêtes
Le schéma conceptuel de l'enquête, les règles de
vérification ne sont jamais parfaitement au point a priori. La pratique de l'enquête
elle-même apporte des enseignements qui conduisent à rectifier la conception initiale.
Les difficultés rencontrées lors de la collecte permettent de repérer des défauts dans
les nomenclatures et la rédaction du questionnaire : une question qui reçoit souvent une
réponse erronée (ou pas de réponse du tout) doit être modifiée ; en outre, le contact
avec la population étudiée renseigne de façon plus précise sur ses possibilités de
réponse, et cela peut conduire à une nouvelle conception du questionnaire.
Pour apprécier la qualité des méthodes de vérification, on
aura intérêt à retourner auprès d'un échantillon de personnes interrogées et à
examiner avec elles le sort qui a été fait à leur réponse, les corrections qui lui ont
été apportées. Le contrôle nécessite une bonne collaboration entre ceux qui ont
conçu l'enquête et ceux qui la réalisent, et également de bonnes relations avec les
personnes enquêtées. Pour que les enseignements recueillis sur la pertinence du cadre de
l'enquête lors des opérations de collecte puissent être effectivement utilisés afin
d'améliorer l'instrument, il faut qu'il n'y ait pas de division du travail entre la
conception et l'exécution, mais répartition des tâches.
L'organisation de systèmes statistiques
Lorsque l'objet étudié est complexe et requiert des
observations différentes selon leur degré de détail et leur périodicité, l'appareil
statistique ne comporte pas une mais plusieurs enquêtes : c'est le cas dans l'industrie,
qui est observée simultanément à l'aide d'une enquête annuelle portant sur les
entreprises, d'enquêtes à périodicité variable (mensuelles ou trimestrielles pour la
plupart) portant sur les fractions d'entreprises et relatives aux productions, des
déclarations fiscales sur les bénéfices et les salaires, des déclarations sur l'emploi
collectées par établissement, des documents fournis à la douane, des enquêtes de
conjoncture, etc.
Les enquêtes statistiques - et aussi, dans la mesure du
possible, les sources administratives - doivent être coordonnées si l'on veut qu'elles
donnent des résultats comparables, et qu'elles soient utilisables à des fins de
vérification mutuelle : les nomenclatures doivent être bien articulées, ainsi que la
définition des unités. Par exemple, si l'une des enquêtes porte sur des entreprises et
l'autre sur des fractions d'entreprises, il faut savoir quelles sont les fractions que
comporte une entreprise pour mettre les résultats des deux enquêtes en regard.
Soulignons qu'il n'est pas indispensable que les choix conceptuels soient identiques pour
chaque source, ce qui induirait souvent une uniformité excessive ; mais il faut que leurs
articulations d'une source à l'autre soient bien connues.
La coordination des répertoires, en particulier, facilite les
fusions de fichiers ; des doubles emplois partiels volontaires (une même question posée
dans deux enquêtes différentes) permettent de s'assurer de l'homogénéité des
réponses ; en cumulant les résultats d'enquêtes à périodicité courte, on obtient une
évaluation de ce que donnera l'enquête à périodicité plus longue et en même temps un
moyen pour la vérifier.
Des enquêtes par sondages peuvent être réalisées sur des
échantillons soit exclusifs (lorsqu'on ne veut pas interroger deux fois la même unité),
soit inclusifs (lorsqu'on souhaite pouvoir fusionner les réponses à deux enquêtes
différentes).
La gestion coordonnée de plusieurs enquêtes, avec les
relations qu'elle implique entre les répertoires et les nomenclatures, les
perfectionnements qu'elle permet pour les procédures de vérification, les fusions de
fichiers qu'elle facilite, conduit à la conception de véritables systèmes
statistiques (10) dont les capacités en matière de production d'information sont
multipliées. La conception de tels systèmes réclame un lourd travail d'organisation et
de technique, notamment pour les informaticiens. Comme toujours, la lourdeur de ce travail
risque d'être la cause indirecte de rigidités : lorsque des adaptations à des
situations ou des besoins nouveaux seront nécessaires, on reculera devant la nécessité
de remettre en question des investissements très lourds ou, pis encore, on ne percevra
même pas le besoin d'adaptation parce que l'on sera entièrement accaparé par la gestion
courante. L'organisation des systèmes statistiques doit être assez souple pour que leurs
responsables restent capables de percevoir la nécessité d'un changement et de s'y
adapter.
Les opérations régulières de production d'information, les
enquêtes lourdes, doivent donc être complétées par des opérations légères et
exploratoires ; l'introduction d'opérations nouvelles ou de modifications doit être
organisée selon des étapes analogues à celles de l'industrie (recherche-développement,
qualification, fabrication, etc.). Nous n'irons pas plus loin dans le détail, car nous
entrons ici dans le domaine de la statistique-fiction : aucune opération n'est conforme
aux schémas que nous venons de décrire, qui ne sont que l'horizon de l'évolution
technique tel que le perçoivent plus ou moins clairement les praticiens.
Cependant l'organisation de systèmes statistiques, parfaitement
logique et souhaitable au plan technique, risque de conduire à des résultats absurdes,
à une bureaucratie de cauchemar, si la technique s'autonomise au point de masquer
l'importance de la méthode statistique, de l'adaptation fine à un besoin d'information
extérieur. Comme tout instrument qui se complique, s'institutionnalise et emploie un
grand nombre d'individus dans des tâches séparées, la statistique risque de tourner à
vide, et ce risque est d'autant plus grand que son organisation est plus poussée : pour
éviter cet écueil, toute systématisation doit être accompagnée d'un approfondissement
de la réflexion sur le rôle de l'instrument.
La description de la technique statistique que nous venons de
donner souffre de nombreuses lacunes, et la praticien sera peut-être choqué par la
désinvolture avec laquelle nous avons expédié en quelques mots des points qui auraient
pu justifier des développements plus amples et plus nuancés. Mais on pourrait écrire
sur la technique statistique un livre entier, et même plusieurs, sans venir à bout de sa
description : notre propos n'était ici que de fournir les indications générales
nécessaires pour entrer, si l'on peut dire, dans l'esprit de cette technique.
Cette technique est toute moderne, marquée par les
possibilités offertes par l'outil informatique ; si elle répond à des exigences
logiques qui ne sont pas récentes, elle leur répond dans des formes nouvelles.
L'artisanat sympathique du statisticien d'avant-guerre, qui réalisait et exploitait des
enquêtes ingénieuses avec de faibles moyens et un personnel réduit (11), s'est
transformé en une vaste organisation dont les méthodes sont encore tâtonnantes mais qui
n'en utilise pas moins un vocabulaire caractéristique : production, gestion, système,
planification. Ce travail emploie des équipes nombreuses et spécialisées dans des
tâches distinctes (administration, organisation, conception, collecte, informatique,
coordination, etc.). Bref, la statistique s'est industrialisée, avec les avantages et les
inconvénients que cela comporte et que chacun peut apprécier à sa façon. C'est cette
nouvelle statistique que nous avons décrite, et il se peut que cette description paraisse
un peu étrange à des personnes qui ont travaillé ou travaillent encore selon des
procédures " artisanales ".
L'organisation du travail statistique a été profondément
renouvelée, comme dans les autres branches (notamment les banques et les assurances) où
le travail de bureau s'est à la fois rapidement développé et automatisé. Ce
développement, qui a provoqué la banalisation de certaines tâches, s'est réalisé dans
une période où, par ailleurs, le niveau des études scolaires avait augmenté : la
relation entre l'organisation du travail, la formation intellectuelle et les perspectives
professionnelles est généralement peu satisfaisante pour les personnels. En ce qui
concerne la statistique (et aussi l'informatique de gestion dans les entreprises), on peut
s'interroger, par exemple, sur l'organisation du travail qui prévaut dans les ateliers de
saisie, où des dizaines de personnes tapent à longueur de journée sur des claviers pour
transcrire sur support informatique le contenu des questionnaires. Les capacités de ces
personnes ne pourraient-elles pas être utilisées de façon plus intelligente et plus
féconde ? Les efforts consacrés aux enquêtes ne pourraient-ils pas être répartis
autrement ? Est-on certain que les enquêtes lourdes soient toutes indispensables ? Ne
pourrait-on pas obtenir une information comparable ou même meilleure en réalisant des
opérations plus légères, mais mieux conçues ? Enfin et surtout, est-on certain de
consacrer assez d'efforts à l'exploitation et à la publication d'enquêtes dont la
saisie et la vérification ont demandé un travail énorme ?
- Expression caractéristique : pour un statisticien, réaliser une enquête, c'est
" aller au charbon ".
- On peut trouver un exposé technique beaucoup plus complet que le nôtre dans le
livre (un peu ancien, car il a été rédigé avant l'ère de l'informatique), de G.
Chevry Pratique des enquêtes statistiques, P.U.F., 1962.
- Nous nous sommes en fait inspiré des enquêtes industrielles pour définir notre
" opération type ".
- Le vocabulaire est ici un peu indécis. Certains tendent à réserver
l'appellation de " répertoire " à de gros instruments d'immatriculation comme
S.I.R.E.N.E. (entreprises et établissements) ou comme le répertoire d'identification des
personnes. On appellerait alors " fichier de lancement " ce que nous nommons ici
répertoire. Le choix des mots prête donc à discussion, mais la chose est claire.
- Système informatique pour le répertoire des entreprises et des établissements.
- C. Gouriéroux, Théorie des sondages, E.N.S.A.E., janvier 1979.
- Chevry, op. cit.
- Si une nomenclature en 20 postes est codée de 01 à 20, des codes comme 1A ou 32
seront signalés par des messages d'erreur.
- Cf. C. Chiaramonti, " Les statistiques, l'information d'origine
administrative et la télématique " in Courrier des statistiques, n° 7, juillet
1978.
- Un " système statistique d'entreprises " est en cours de réalisation.
Nous ne connaissons pas d'autres cas de ce type d'organisation, qui devrait néanmoins se
répandre en raison des possibilités ouvertes par l'informatique.
- A. Sauvy, De Paul Reynaud à Charles de Gaulle, Casterman, 1972.