|
« The Web is an engineered space created through
formally specified languages and protocols. However, because humans are the
creators of Web pages and links between them, their interactions form emergent
patterns in the Web at a macroscopic scale » (Tim
Berners-Lee, Wendy Hall, James Hendler,
Nigel
Shadbolt, Daniel J. Weitzner, « Creating
a Science of the Web », Science, 11 août 2006).
« Combine the Internet, wireless
satellites, and fiber optics, great leaps in computing power (through circuits
not wider than a few atoms), a quantum expansion of broadband connection
(transmitting more and faster digital data into homes and offices through
networks of fiber-optic cables and constellations of satellites), a map of the
human genome and tools to select and combine genes and even molecules and you
have a giant, real-time, global bazaar of almost infinite choice and
possibility. » (Robert Reich, The Future of Success, Working and Living in
the New Economy, Knopf 2000).
Résumé
Lespace géographique est pour chacun lobjet
dune expérience familière. La téléphonie a cependant procuré lubiquité au
signal vocal, lInternet la procure à la ressource informatique (textes,
images, sons et données). Larrivée des téléphones mobiles, puis des terminaux
mobiles, a rendu lubiquité absolue : le corps de lutilisateur étant équipé,
celui-ci na plus besoin pour accéder au service de se trouver dans un local
équipé d'un terminal fixe.
Lubiquité du service ouvre un espace nouveau,
celui des signaux et des ressources informatiques dotées dubiquité ; nous
lappellerons « espace logique ». Cet espace comporte des limites et des distances,
mais elles diffèrent de celles qui existent dans lespace géographique.
On peut doter lespace logique doutils qui
permettent
à lutilisateur de sy repérer. Ces outils sarticulent selon une architecture
en couches ; ils sappuient sur la correspondance quun traitement statistique
fait apparaître entre segments dutilisateurs et segments de ressources.
Enfin, la rencontre de lespace logique et de lespace géographique est
loccasion dune offre de services spécifique.
Faut-il dire mobilité ou ubiquité ?
Depuis 1876 il nest plus
indispensable, pour converser avec une personne, de se trouver à portée de
voix : le téléphone a conféré lubiquité au signal vocal. Lorsque seuls
des téléphones fixes étaient disponibles, il fallait cependant pour pouvoir
téléphoner se trouver près dun poste téléphonique (dans lappartement, au
bureau, dans une cabine). A lubiquité du signal, le téléphone mobile a ajouté
lubiquité de laccès : il équipe le corps de lutilisateur et non
plus un local. Lubiquité de la téléphonie est ainsi devenue totale, aux zones
blanches du réseau près.
Depuis 1991 lutilisateur du
Web accède à des serveurs dont la localisation lui importe peu : que le serveur
soit proche ou à lautre bout du monde, le délai daffichage est analogue. Le
Web confère ainsi lubiquité aux ressources informatiques,
celles-ci étant également accessibles à partir de tout ordinateur connecté au
réseau. Lorsque lordinateur sera devenu lui aussi mobile, lorsquil équipera le
corps de lutilisateur
linformatique bénéficiera elle aussi de lubiquité totale.
Pour décrire cette évolution on
utilise par analogie avec la téléphonie mobile le terme de mobilité.
Mieux vaut dire ubiquité : lutilisateur, quil soit mobile ou non, se
trouve en effet plongé dans un espace logique où la distance géographique
nexiste pas. Dans cette expression lépithète « logique » ne renvoie pas au
raisonnement mais au langage (λογός signifie à la fois parole et
raison). Quant au mot « espace », il prend son sens car on peut, parmi
les ressources, définir des limites et une « distance » (non géographique).
Les routes, les rues des
villes, les portes des immeubles et des appartements délimitent, dans lespace
géographique, des voies daccès licites. Il en est de même dans lespace logique
où les habilitations délimitent les ressources auxquelles un utilisateur
particulier a accès et jouent donc le même rôle que les murs, portes et serrures
de lespace géographique.
Entre un utilisateur et une ressource on peut en outre définir une distance :
celle de lintelligibilité de cette ressource pour cet utilisateur, ou
encore (et cela revient au fond au même, car nous ne comprenons que ce qui nous
intéresse), celle de lintérêt quelle présente pour lui.
On retrouve ainsi dans lespace logique, sous des formes certes différentes, les
limites, la distance qui nous sont familières dans lespace
géographique.
On peut aussi y définir dautres
distances : une distance entre utilisateurs, dautant plus grande que leurs
centres dintérêt sont plus éloignés ; une distance entre les ressources,
dautant plus grande que leur contenu est plus différent. Cest (cf. annexe)
après avoir défini ces deux distances que lon peut évaluer, en sappuyant sur
lobservation statistique, la distance entre un utilisateur et une ressource.
Lubiquité logique que
procure lInternet est absolue (sous réserve des droits daccès). Lubiquité
physique quil procure est par contre, comme en téléphonie, limitée aux
signaux : le réseau peut transmettre le signal vocal, ou limage dune personne,
ou encore le codage de la forme géométrique dun objet physique que le récepteur
pourra reproduire, mais il ne peut pas transporter des objets physiques.
Le Web hier et aujourdhui
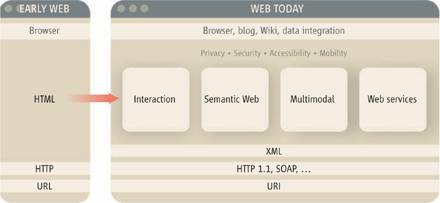
(Source : World Wide Web Consortium)
Lors de sa création en 1991 le Web comportait des
textes codés en HTML (Hypertext Markup Language), transmis via le
protocole HTTP (Hypertext Transfer Protocol) et consultables en
utilisant un navigateur pointant vers une adresse URL (Universal Resource
Locator).
Les utilisateurs disposent aujourdhui dune
panoplie plus large : les SVG (Scalable
Vector Graphics),
le Web sémantique, des outils multimédia (navigateurs vocaux par exemple), des
descriptions de services. Les ressources sont codées en XML (eXtensible
Markup Language), transmises par les protocoles HTTP 1.1 ou SOAP
(Simple Object Access Protocol) et leur adresse est un URI (Uniform
Resource Identifier).
Il suffit de prolonger par la pensée cette
évolution du Web pour anticiper les outils dont nous disposerons demain.
Comment cela va-t-il se passer pratiquement ?
Projetons-nous dans un avenir
point trop lointain, mais suffisamment éloigné pour que les conséquences des
tendances actuelles aient pu se déployer : disons donc dans dix ou quinze ans, en 2016
ou 2021
[11].
Dans les pays riches, les
utilisateurs accèdent à des réseaux mobiles à haut débit (de lordre de 10
Mbit/s) et, dans leur entreprise comme à domicile, à des réseaux à plus haut
débit encore (de lordre de 100 Mbit/s). Ils disposent dun terminal mobile,
successeur du téléphone mobile daujourdhui, quils portent sur eux et qui leur
permet daccéder à leurs ressources à tout moment et où quils soient, et de
terminaux fixes,
équipés dun écran de grande dimension à haute définition (ou de plusieurs
écrans) et dun clavier, permettant daccéder aux services et aux ressources
selon une excellente ergonomie.
Les utilisateurs ont ainsi
accès à des ressources informatiques publiques, personnelles et professionnelles
(configuration de linterface homme machine, fichiers, applications) résidant
sur des serveurs sécurisés.
Lorsquils se connectent les utilisateurs sidentifient et authentifient leur
identification, après quoi ils accèdent aux ressources dans la limite de leurs
habilitations.
Les terminaux fixes sont
installés au domicile, au lieu de travail et dans des lieux publics. Ils
rassemblent les fonctions aujourdhui remplies par lordinateur, le téléviseur
et la chaîne à haute fidélité.
Si lutilisateur sinstalle en face dun terminal fixe et demande la connexion,
son terminal mobile émet vers le terminal fixe les informations nécessaires à
lidentification : le terminal fixe donne alors, après saisie dun mot de passe,
accès aux ressources de lutilisateur.
Réseaux et terminaux donnent
accès à une plate-forme téléphonique, audiovisuelle et informatique sur laquelle
sont offerts des services diversifiés, gratuits ou payants. Laccès aux
ressources audiovisuelles, par exemple, est outillé de fonctions de recherche et
de tri qui ont transformé les conditions pratiques de la programmation
individuelle.
La plate-forme comporte des outils sécurisés de gestion des comptes bancaires.
Divers équipements (automobile, distributeur automatique de billets, portes à
ouverture automatique, caisses des magasins etc.) sont eux aussi communicants et
obéissent aux ordres de lutilisateur.
Par rapport à la situation
présente, voici les changements que cela implique :
-
le téléphone mobile est devenu un
terminal mobile qui incorpore, outre les fonctions du téléphone et de
lordinateur, celles du GPS, du magnétophone, de lappareil de photo, de la
caméra, du téléviseur ; s'il est raccordé à des capteurs, il peut collecter
l'électrocardiogramme, la tension etc. et envoyer des alertes à un centre de
télésurveillance médicale. Il est doté dun écran lisible.
Le clavier est soit dépliable (des claviers dépliables équipent déjà certains
Palmtops), soit une image projetée par un laser sur une surface plane etc. ;
-
les ressources informatiques ne
résident pas sur le disque dur du terminal mais sur des serveurs sécurisés
(chiffrement, back up) accessibles via lInternet, exploités par des
opérateurs spécialisés et situés nimporte où dans le monde.
Une entreprise peut soit exploiter elle-même les serveurs sur lesquels résident
ses ressources informatiques, soit confier cette exploitation à des opérateurs ;
-
les terminaux fixes et les terminaux
mobiles sont en principe des terminaux « bêtes », équipés seulement du logiciel
nécessaire pour la connexion à la ressource informatique et laffichage de
linterface. Cela permet un démarrage rapide et laffichage pratiquement
instantané de linterface de lutilisateur. Ils peuvent toutefois, en option,
être équipés comme les ordinateurs daujourdhui du logiciel et de la mémoire de
masse nécessaires pour une utilisation hors réseau.
Les réseaux mobiles à haut
débit et les réseaux fixes à très haut débit apparaissent alors comme
complémentaires.
Architecture de lespace logique
Larchitecture de lespace logique peut se
représenter selon un modèle en couches (figure 1) :

Figure 1
- infrastructure du réseau : deux réseaux daccès
(mobile à haut débit, fixe à très haut débit) et un réseau de transport,
lInternet, avec les outils informatiques de gestion et supervision
(adressage, réplication, dimensionnement
etc.) ;
- services de plate-forme informatique : serveurs
(processeurs, systèmes dexploitation, outils de supervision), mémoires,
sécurité (chiffrement, back up, protection contre les intrusions,
antivirus etc.). Ces services traitent de la physique informatique et
assurent la fiabilité et la disponibilité du service ainsi que la protection
des ressources contre les indiscrétions et les attaques ;
- services dintermédiation : aide à la recherche
des ressources qui correspondent aux besoins de lutilisateur (moteurs de
recherche, classification documentaire, dissémination sélective, publish
and subscribe etc.). Lintermédiation est associée, pour les ressources
payantes, à des services financiers ; pour les produits matériels (livres,
équipements etc.) à des services de proximité ;
- services financiers : traitement automatique des
effets de commerce (dettes, créances, ordres de virement, répartition entre
ayants droit) échangés par les utilisateurs et les fournisseurs ;
- services de proximité : livraison, installation,
formation des utilisateurs, entretien, dépannage etc.
- services éditoriaux : ressources gratuites ou
payantes mises à disposition sur le réseau (logiciels, textes, musique,
audiovisuel, données etc.) ;
- gamme des terminaux, divisée en deux
familles (fixes et mobiles).
Changements par rapport à aujourdhui
On retrouve dans ce monde
certains services que nous connaissons déjà : le commerce électronique est en
place avec les outils de paiement informatisés et il sarticule avec des
services de livraison pour les produits pondéreux. Le futur apportera donc non
pas de lémergence de services entièrement nouveaux, mais lexploitation
systématique, plus puissante aussi parce que disposant de moyens nouveaux, des
services qui existent déjà aujourdhui.
Cette intensification a des
conséquences pratiques : elle « change la vie » tout comme le téléphone mobile,
qui lui aussi navait « rien de nouveau », la changée lorsquà partir de 1995
son prix a baissé, que sa couverture géographique sest densifiée et quil est
devenu un produit de masse.
La baisse du prix du haut
débit, son extension aux réseaux mobiles, la généralisation de la tarification
forfaitaire, les progrès dans lergonomie du terminal mobile et du terminal fixe
auront élargi et modifié la relation entre les utilisateurs (personnes ou
entreprises) et la ressource informatique. Des services dont le « business
plan » aurait été auparavant peu crédible seront rentables. Des équipements qui
navaient jamais été mis en réseau (systèmes darrosage, équipements ménagers,
chauffage etc.) lui seront raccordés, ce qui facilitera leur télécommande, leur
télémaintenance et le téléchargement de nouvelles versions de leur logiciel.
Linformatisation des transactions facilitera laccès des PME à des services de
comptabilité, de gestion dagenda etc., ainsi que le partage des centres
dappel.
La ressource informatique dune
personne contiendra son dossier médical, lhistorique de ses comptes bancaires,
de ses revenus et de ses dépenses, celui de son cursus scolaire et des
formations quil a suivies etc. Laccès à ces informations doit être sécurisé
mais lutilisateur pourra sil le souhaite louvrir de façon permanente ou
temporaire à des personnes quil autorise (médecins, administration fiscale
etc.).
Cependant tout ne sera pas
automatisé : parallèlement à la croissance de la part prise par lautomate dans
les services, croîtra pour lutilisateur le besoin dune assistance et dun
dialogue avec un être humain, que ce soit par réseau (centre dappel,
visiophonie) ou en face à face, afin de traiter les problèmes qui ne sont pas du
ressort de lautomate (expliquer, comprendre). Il en résultera un changement de
la structure de lemploi.
* *
Lubiquité de lespace logique
permettra des usages aujourdhui inédits. Il se peut par exemple quune personne
qui habilite ladministration fiscale à consulter automatiquement lhistorique
de ses revenus bénéficie dune réduction de limpôt sur le revenu en
contrepartie de la fiabilité de linformation et de la commodité daccès. Une
personne qui consulte un médecin pourra, pendant la durée de la consultation,
lui donner accès à son dossier médical, à lhistorique des prescriptions et
traitements etc.
Outils de lespace logique
Les outils nécessaires à la
conquête de lubiquité sont en cours de mise au point, voire déjà disponibles :
réseaux à haut débit, outils de classement et de recherche, de chiffrement et de
gestion des habilitations etc. Loutillage avance et la synergie des divers
outils converge, mais sans toutefois semble-t-il que le point vers lequel
soriente cette convergence soit clairement perçu : les réseaux à haut débit et
lUMTS se mettent en place sans que lon sache exactement à quoi ils vont
servir, il en est de même des outils de recherche.
Il est dautant plus
intéressant dexplorer les conséquences prévisibles de cette synergie.
A chaque utilisateur, on pourra
associer dans lespace logique un domaine comportant lensemble des
ressources susceptibles de lintéresser. Ce domaine sera défini (1) par
segmentation, le domaine étant commun à tous les utilisateurs appartenant à
un même segment ; (2) par personnalisation, lobservation des requêtes et
du comportement dun utilisateur permettant de préciser linformation sur ses
besoins que donne la segmentation. On pourra lui fournir des outils qui :
- facilitent la recherche des
ressources intéressantes (moteurs de recherche, mais aussi synthèses, critiques,
paratexte etc.) ;
- indiquent, de façon
proactive, les changements survenus dans le contenu de son domaine (nouvelles
ressources etc.) ;
- permettent de prendre
connaissance du contenu de son domaine, de ses frontières, des relations quil
entretient avec les domaines connexes, des extensions possibles de son champ
dintérêt.
Des communautés dutilisateurs
pourront se former à lexemple de ce qui se passe aujourdhui sur Flickr où lon
stocke, documente et partage des photographies, lindex documentaire amorçant le
fonctionnement communautaire en facilitant la recherche.
* *
Il est difficile de recenser
a priori tous les usages possibles du terminal mobile, toutes les situations
dinteraction, de même quil aurait été très difficile à Gutenberg de prévoir
toutes les utilisations de limprimerie, des journaux aux livres et magazines
jusquaux notices techniques et fiches que lon trouve dans lemballage des
médicaments. Cest un thème de recherche en soi, qui peut tout au plus samorcer
par lobservation et lextrapolation raisonnée des pratiques actuelles.
Les possibilités ne seront pas
immédiatement utilisées : si la ressource informatique personnelle semble par
exemple le lieu naturel où lon peut stocker un dossier médical, il faudra du
temps pour que la corporation médicale, le milieu hospitalier, acceptent de sy
adapter. De façon générale les institutions, confrontées à une transformation
profonde de leurs procédures, seront lentes à en tirer parti.
Certaines personnes vont
résister, car linformatisation de la vie personnelle ne sera pas bien vécue par
tout le monde ; elle posera dailleurs, tout comme la fait le téléphone mobile
des problèmes de savoir-faire et de savoir-vivre nouveaux et irritants.
Les prédateurs chercheront les
failles éventuelles des systèmes de chiffrement et de sécurité : lespace
logique devra donc, pour être habitable, être équipé de dispositions juridiques,
surveillé par une gendarmerie vigilante, sanctionné par un appareil judiciaire
qualifié.
Les entreprises, enfin,
rencontreront dans lespace logique de nouvelles formes de commerce et
dorganisation de la force de travail auxquelles elles devront elles aussi
sadapter.
Les efforts dorganisation
personnelle et collective, la transformation des institutions, prendront plus de
temps que linnovation technique.
* *
Lévocation de ce futur proche
éveille inévitablement une question à la fois naïve et fondamentale : « en quoi
cela nous rendra-t-il plus heureux, plus intelligents ? ». La réponse est
implacable : ni le bonheur, ni lintelligence ne dépendent des outils qui, comme
le téléphone, lautomobile, lavion, la télévision et demain les réseaux à
haut et très haut débit, le terminal mobile et son couplage au terminal fixe
ne font que modifier notre rapport au temps et à lespace. Le mathématicien le
plus savant, pour ne prendre que cet exemple, se contente dun crayon et de
papier. Lespace logique ne nous apporte ni le bonheur, ni lintelligence : il
pourra être utilisé par le barbare comme par le sage, et certains sinquiètent
déjà des moyens quil offrira aux terroristes.
Construire sans trop tarder les
savoir faire et les savoir vivre que nécessite lespace logique apparaît alors
comme un enjeu pour la civilisation. Cest pourquoi il importe de voir où
conduit lévolution actuelle : il ne sagit pas de faire lapologie béate de la
technique, mais de se préparer à la vie dans lespace logique.
Mise en perspective : temps et espace
Pour comprendre la nature et
les enjeux de lespace logique il est utile de se tourner vers lhistoire.
Lespace logique est plus
ancien que le « cyberespace » qui sest ouvert sur lInternet. Nous nous
trouvons en effet déjà dans lespace logique pendant une conversation, au
cinéma, au théâtre, devant notre téléviseur. Nous y accédons aussi lorsque nous
entrons dans une bibliothèque : « la lecture de tous les bons livres est comme
une conversation avec les plus honnêtes gens des siècles passés ».
Dans une bibliothèque par
exemple, et sous la double contrainte de ses préférences et des limites du
catalogue, le lecteur est affranchi des contraintes de lespace géographique et
du temps. Comme tous les monuments, un texte peut être détruit ou mutilé mais,
alors quaucun monument ne peut rester intact, certains textes nous sont à
travers les millénaires et les continents parvenus tels quils étaient sortis
des mains de leur auteur : si nous savons les lire, nous entrons en conversation
avec lui. Rien nest plus émouvant que ces échanges par delà la mort, par delà
les frontières du langage et de la culture. La political correctness
prétend cependant les proscrire sous prétexte que leurs auteurs seraient des
morts blancs du sexe masculin, « they are all white, male and dead »...
On peut donc dire que lespace
logique dont nous parlons na rien de nouveau, et il est vrai quil ne faut pas
sexagérer sa nouveauté. Toutefois il nest pas indifférent que lon puisse y
disposer grâce au Web dune plus grande diversité de ressources, doutils plus
efficaces de recherche et de sélection.
Lespace logique, devenu sur
lInternet accessible à tout moment et en tous lieux, équipé doutils de
recherche et de classement, sy manifeste dune façon plus évidente et
qualitativement plus complète quil ne le faisait auparavant dans les
bibliothèques. Cest cet espace ainsi complété, achevé, que nous voulons
explorer ici. Mais nous laborderons en gardant en mémoire les leçons que lon
peut tirer des pratiques immémoriales de la conversation, de la lecture, du
spectacle.
* *
Lespace logique est dabord la
négation de lespace géographique. Déjà, dans les entreprises, lIntranet a
permis de combler (voire de retourner) lécart de compétence professionnelle qui
existait entre la direction générale et les directions régionales.
Une part des travaux de lentreprise seffectue dans lespace logique :
interprétation des textes, classement comptable, programmation informatique etc.
Le télétravail sera donc mis en uvre pour les activités pour lesquelles il est
économiquement efficace (cest-à-dire : non pas à 100 % ni pour toutes les
activités, mais de façon significative tout de même).
Lespace logique est aussi en
relation avec lespace géographique : le commerce des produits physiques sur le
Web se boucle nécessairement par une livraison ; la localisation dappel est à
la base de plusieurs des services offerts sur les réseaux UMTS ; les
automobilistes utilisent des systèmes de navigation qui sappuient sur le GPS.
Voici une exploration (non exhaustive) des services qui concrétisent
larticulation entre espace logique et espace géographique :
Localisation
La localisation, fournie de
façon précise par le GPS incorporé dans le terminal mobile, est un des attributs
de lutilisateur et contribue à la définition des ressources qui lintéressent :
il sintéresse potentiellement à sa région, sa commune, aux manifestations
culturelles locales, aux commerçants du coin, aux services de proximité qui
peuvent lui être offerts.
Il peut être utile aussi de
localiser des personnes dépendantes (enfants, personnes âgées).
Déplacements
Le GPS permet à lutilisateur
de savoir où il se trouve pendant ses déplacements. Les systèmes de navigation
peuvent équiper le piéton aussi bien que lautomobile.
Le calcul ditinéraire peut se
faire en temps réel, cest-à-dire tenir compte de la situation présente du
trafic (chantiers, embouteillages, manifestations etc.).
Le piéton peut localiser les
taxis et transports en commun disponible : emplacement des stations et arrêts,
durée dattente, durée prévisible du voyage.
Ressources physiques
Le terminal mobile peut :
- informer lutilisateur sur
les ressources physiques proches et ouvertes (pharmacies, hôpitaux, distributeurs
automatiques de billets, agences bancaires, bureaux de poste, restaurants,
cinémas etc.) [10] ;
- afficher des vitrines
virtuelles (quand on passe devant un immeuble, indique des magasins dont
certains ne se voient pas depuis la rue) ;
- donner une information
météorologique localisée ;
- signaler au touriste des
monuments intéressants, des expositions etc., et lui donner des explications
historiques sur les lieux quil parcourt ;
- indiquer les noms des
habitants dun immeuble, etc.
Système dinformation géographique
Lutilisation locale dun SIG
fournit des informations diverses et à des échelles diverses ; elle permet de
localiser les réseaux qui se trouvent en sous-sol, de visualiser le cadastre
etc.
*
*
Annexe : outils mathématiques
Les utilisateurs du Web
disposent actuellement de moteurs de recherche dont Google est le plus fameux ;
dencyclopédies en ligne dont Wikipedia est la plus connue. Les liens hypertexte
leur permettent de « surfer » pour trouver des ressources inconnues et,
daventure, intéressantes.
Les outils actuellement
disponibles, aussi puissants et utiles quils soient, ont des limites. Google
indexe des chaînes de caractère et les résultats quil fournit sont altérés par
des homonymies. Le surf est aléatoire. Les outils de dissémination sélective,
censés apporter automatiquement à lutilisateur des informations qui
lintéressent, sont dans les limbes.
Cependant les recherches en
cours ont entrepris de corriger ces défauts et esquissent loutillage de
lespace logique. Des outils sémantiques visent à supprimer les homonymies dans
les moteurs de recherche [16] ; le contenu du Web est soumis à des outils de
classification automatique délimitant des clusters de textes [9] ; des
outils de datamining examinent les co-occurrences lexicales et détectent
les tendances de lévolution des contenus
[14]; les annonceurs observent le comportement des utilisateurs de lInternet
[8].
* *
Entre un utilisateur et une
ressource, on peut définir une distance qui est celle de lintelligibilité
ou, ce qui revient au fond au même, de linformation que ce texte peut
apporter au lecteur en prenant « information » non au sens qua ce mot dans la
théorie de Shannon [13] mais au sens étymologique : une information, cest
quelque chose qui vous in-forme, qui modifie ou complète la forme
intérieure de votre représentation du monde, qui vous forme vous-même.
Linformation ainsi conçue a une signification : elle suscite une action
de la part de celui qui la reçoit ou du moins elle modifie (trans-forme)
les conditions de son action future. Plus un texte peut apporter dinformation à
un lecteur, plus il présente dintérêt pour lui : intelligible,
intéressant, informatif sont donc des synonymes.
Pour pouvoir recevoir une
information, il faut avoir été formé, et cest en recevant de linformation que
lon se forme. Lamorce de ce cycle est enfouie dans les origines de la personne
tout comme lamorce du cycle de la poule et de luf est enfouie dans les
origines de la vie.
* *
Notons U lensemble des
utilisateurs, R lensemble des ressources. Supposons définie une distance d(u,
r) entre le lecteur u et le texte r, dautant plus petite que ce texte est plus
intelligible pour ce lecteur. Nous appellerons « domaine du lecteur u »
lensemble D(u) des ressources dont la distance au lecteur est inférieure à un
seuil conventionnel s :
D(u) = {r | d(u, r) < s}.
Nous appellerons « lectorat de
la ressource r » lensemble L(r) des utilisateurs dont la distance à la
ressource est inférieure à s :
L(r) = {u | d(u, r) < s}.
Considérons un sous-ensemble D
de R. Nous noterons L(D) lensemble des lecteurs intéressés par toutes les
ressources que contient D :
L(D) = {u | D
⊂
D(u)}.
Considérons un sous-ensemble L
de U. Nous noterons D(L) lensemble des ressources qui intéressent tous les
membres de L :
D(L) = {∩D(u)
| u ∊
L}.
Nous dirons que L et D sont en
correspondance si L(D(L)) = L et D(L(D)) = D. Nous allons
esquisser la démarche qui permet de construire deux segmentations (lune des
utilisateurs, lautre des ressources) dont les segments mutuels sont
statistiquement en correspondance.
* *
Les outils en cours de mise au
point utilisent des techniques statistiques connues et éprouvées (notamment les
Support Vector Machines),
mais à une échelle et sur des volumes qui exigent des algorithmes et des
processeurs puissants. Pour classer des textes, ils considèrent la taille, la
structure formelle, les métadonnées et les co-occurrences lexicographiques. Pour
classer des images et les enregistrements audio ou vidéo, ils considèrent les
métadonnées (index etc.) et, plus difficilement, les formes représentées ainsi
que les paramètres techniques de limage ou du son.
Dans tous les cas, il faut
définir une distance entre les ressources, puis une distance entre agrégats de
ressources ; on peut alors, par classification ascendante hiérarchique,
construire une ultramétrique sur lensemble des ressources puis obtenir une
segmentation en « coupant les branches les plus longues » de larbre qui
représente lultramétrique.
Si lon veut que le Web puisse
signaler à lutilisateur de façon proactive les ressources susceptibles
dintéresser celui-ci, il faut segmenter la population des utilisateurs en
utilisant dabord des données « intrinsèques » (cest-à-dire
indépendantes de lusage quils font de la ressource) observées par enquête
auprès dun échantillon représentatif : âge et sexe, catégorie
socioprofessionnelle, lieu de résidence, lieu de travail, métier, fonction dans
lentreprise, statut matrimonial, nombre et âge des enfants, hobbies etc.
Puis on observe, toujours sur
le même échantillon, les pratiques dans lutilisation du Web et on demande
éventuellement aux utilisateurs de noter lintérêt des ressources quils
consultent. On établit un tableau des fréquentations en croisant la segmentation
des utilisateurs et celle des ressources (figure 2).
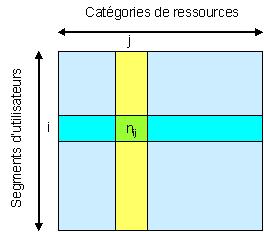
Figure 2
Une analyse factorielle des
correspondances [17], réalisée sur ce tableau, met en évidence la corrélation
entre les deux segmentations (cest parce que lon recherche cette corrélation
quil ne fallait pas prendre en compte de façon prématurée, pour classer les
utilisateurs, les données concernant leurs consultations). Lordre des classes
sur le premier axe de lanalyse fournit un tableau aussi proche que possible de
la forme diagonale (figure 3).
Il est alors possible
dassocier statistiquement à chaque segment des utilisateurs une catégorie de
ressources et inversement. Cela fournit une segmentation globale, définie à la
fois selon les paramètres propres aux utilisateurs et selon ceux des
ressources : les ensembles L et D sont ainsi mis en correspondance. On peut de
la sorte, ayant identifié les ressources qui intéressent le plus un segment
dutilisateurs, amorcer une politique de diffusion proactive.
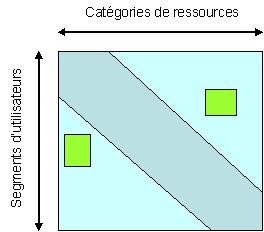
Figure 3
On trouvera en dehors de la
diagonale quelques cases bien remplies faisant exception à la logique
densemble. Cest là un des résultats les plus précieux de lanalyse : ces cases
contiennent des utilisateurs dont le comportement sécarte du comportement
majoritaire, quils soient « en avance » ou « en retard » dans la consultation
des ressources ou pour tout autre raison. Les examiner donne un aperçu sur la
dynamique de la demande.
Lorsque loutillage est ainsi
amorcé, on peut mettre les segmentations à jour en recherchant, parmi les
combinaisons linéaires des données intrinsèques et des ressources consultées par
un utilisateur, celles qui sont les mieux corrélées : il faudra ici recourir aux
techniques de lanalyse canonique [17].
Cette analyse permet de :
- placer un nouvel utilisateur dans
lespace documentaire, une fois connu le segment auquel il appartient (par la
suite, la personnalisation permettra de faire évoluer ce quon lui propose) ;
- signaler aux utilisateurs dun segment
les nouveaux documents qui font partie du segment documentaire qui a priori
les intéresse ;
- fournir à chacun une vue de lespace
logique, de la façon dont il est structuré, et de lendroit où on le situe
lui-même (il peut ainsi organiser des voyages dans cet espace).
- identifier les segments « voisins »,
potentiellement intéressants les ceux des utilisateurs dun segment donné qui
souhaitent élargir leur horizon.
Bibliographie
[1] Francis André, Libre
accès aux savoirs : Open Access to Knowledge, Futuribles 2005.
[2]
Tim
Berners-Lee, Wendy Hall, James Hendler,
Nigel
Shadbolt, Daniel J. Weitzner, « Creating
a Science of the Web », Science 11 août 2006.
[3] Sandra
Braman,
« Transformations
of the Research Enterprise », Educause Review, août 2006.
[4] Sergey
Brin, Lawrence Page,
« The
Anatomy of a Large-Scale Hypertextual Web Search Engine »
in Proceedings of the 7th
International World Wide Web Conference
(Elsevier Science, Amsterdam, 1998), pp. 107-117 : larticle qui décrit les
origines de Google.
[5] Anne Cauquelin,
Fréquenter les incorporels : contribution à une théorie de lart contemporain,
PUF 2006.
[6] Weiguo
Fan, Linda Wallace, Stephanie Rich,
« Tapping
the Power of Text Mining », Communications of the ACM, septembre 2006.
[7] Gérard
Genette, Palimpsestes, Seuil 1982.
[8] Saul
Hansel,
« AdvertisersTrace Paths
Users Leave on Internet »,
The New York Times, 15 août 2006.
[9] Thorsten
Joachims, Learning to Classify Text using Support Vector Machines, Kluwer
Academic Publishers 2002.
[10]
Vassilis Kostakos et Eamonn ONeil, « Designing Urban Pervasive Systems »,
Computer, septembre 2006.
[11] « The
Future of the Internet II », rapport du Pew Internet & American Life
Project, 24 septembre 2006.
[12] Michael
M. Roberts,
« Lessons
for the Future Internet: Learning from the Past », Educause Review
août 2006.
[13]
Claude E. Shannon,
« A
mathematical theory of communication »,
Bell System Technical Journal,
juillet - octobre 1948.
[14] Colin
Stewart, « 'Data
miners' at UCI moving beyond Google », The Orange County Register, 8 août
2006.
[15] Jean-Baptiste Su, « Streamload
: L'avenir du stockage de données privées appartient à Internet »,
LExpansion, 8 septembre 2006.
[16] Michael
Stutz, « Open
source search technology goes beyond keywords », NewsForge, 25
septembre 2006.
[17] Michel Volle,
Analyse des données, Economica 1994.
La gestion des droits
daccès sur le réseau téléphonique est assurée par le HLR (Home Locator
Register), outil déjà ancien construit dans les années 90. Les
opérateurs cherchent à le faire évoluer pour tenir compte de ladressage
IPv6.
Les forums
constituent une masse où saccumule le commentaire du commentaire et où lon
se perd sans trouver de point saillant. Anne Cauquelin [5], se référant à la
philosophie stoïcienne, a parlé des incorporels, du vide qui entoure lobjet
et lui permet dexister devant lattention du lecteur : les mots sont ainsi
entourés dun espace dans lequel ils peuvent signifier quelque chose. Le
forum, étant trop plein, ne laisse pas jouer lespace vide qui rendrait les
mots expressifs. Produire le point saillant (une synthèse, une orientation)
permettrait de valoriser le stock de textes.
Ces fonctions sont
aujourdhui disponibles, mais peu ergonomiques et donc peu utilisées. Les
ressources graphiques et sonores ont besoin dun titre et dun commentaire,
alors que les ressources textuelles peuvent sindexer elles-mêmes. On peut
prévoir des traitements de type textuel qui aident à construire un contexte
dinteraction : à tout texte, le lecteur associe un paratexte [7], une
enveloppe de significations : « je suis en train de lire un roman policier,
je sais ce que lon attend de la lecture dun roman policier ».
Le trafic sera plus
aléatoire que sur le réseau téléphonique en raison de la diversité des
services : il faudra dimensionner le réseau en conséquence.
René Descartes
(1596-1650), Discours de la méthode (1637). Cest sans doute en
sinterrogeant sur la qualité des conversations que lon peut trouver la clé
du choix de ses lectures comme de la façon de lire.
Cela rappelle le cri
par lequel von Stahremberg galvanisait ses troupes : « Wir
wollen keine deutsche Kultur ! Wir wollen keine französische Kultur !
Wir wollen gar keine Kultur !
» et la fameuse phrase de Goebbels « Wenn
ich das Wort Kultur höre, entsichere ich meinen Revolver ».
Les SVM sont un outil danalyse discriminante linéaire, mais dans un espace
où lon a introduit des fonctions puissance ou autre des données observées ;
on obtient ainsi dans lespace dorigine une frontière qui nest pas
linéaire.
|